
depgrapher: Fast Dependency Analysis for Javascript
Where is this module used? Show me a graph of all the modules I import! Visualize the semantic environment of this file!
For these tasks you can write a precise Javascript parser or extract
the ast with an existing tool. And if your project is big enough (or
too big?) it will be slow. What to do?
You can wait, but that’s annoying. Or you can cache, then you trade
speed for cache invalidation, one of the 10 hard problems in
software development (with naming being the other).
Or you analyze your requirements and turn to Unix tools for the rescue.
Requirements
What do you really need? That’s in the tasks at the beginning of this article. In short: local graphs of imports.
What do you have? There are imports:
import 'foo/bar';
And partial imports:
import {
baz,
blue
} from 'moo';
And dynamic webpack imports:
import(/* webpackChunkName: "blah" */ 'blah')
.then(...);
And a few more. What do they have in common?
If you use typical and regular code-style they all map to regex. Too big and annoying regex, but regex nonetheless.
And if you can regex it you can ripgrep.
And if you can ripgrep your project won’t be too big.
The graph
Now that the requirements are clear we assemble simple regular expressions to get all edges and nodes of a graph representing the whole dependency structure of the project. I hear you ask „but didn’t we want just the local area?“ Yes, we did, but ripgrep is fast. And this keeps it simple:
TMPDIR=$(mktemp -d) # working in a TMPDIR to avoid interfering with anything else
rg from\ \' | grep -v '#' > "${TMPDIR}"/graphbody
rg import\ \'".*;" | grep -v '#' >> "${TMPDIR}"/graphbody
rg -o "import\\(.*webpackChunkName.*'.*'\\)" | grep -v '#' >> "${TMPDIR}"/graphbody
This gives us something like the following:
foo/bar.js:import { baz, blue } from 'moo';
foo/bar.js:import(/* webpackChunkName: "blah" */ 'blah')
moo.js:import 'foo/bar';
(yes, we can have cycles. This is JS. The cycle is in pseudo compile-time.)
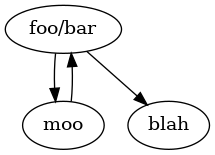
Since these are the edges and nodes of a graph, let’s turn them into a graph. The command line tool for that is Graphviz. It expects a format like the following:
digraph {
"foo/bar" -> "moo"
"foo/bar" -> "blah"
"moo" -> "foo/bar"
}
So we have this huge list of dependencies, one per line, and need to
transform it. The tool for that is sed. Or awk, but I know sed
better, so I use sed.
First cleanup the lines: Filter out anything we don’t need. I’ll show that only for the clearest case (the direct imports); the details for the others are in depgrapher.in.
rg from\ \' | grep -v '#' \
| sed "s/\\.[^.]*:.*from '/ -> /" \ | sed "s/'.*//g" \
| sed -E 's,([^ ]+)/([^ ]+) -> \./([^ ]+),\1/\2 -> \1/\3,' \
| sed -E 's,([^ ]+)/([^ ]+)/([^ ]+) -> \../([^ ]+),\1/\2/\3 -> \1/\4,' \
| sed -E 's,^(.*) -> (.*)$,\2 -> \1,' \
| sed 's,^,",' | sed 's,$,",' \
| sed 's, -> ," -> ",' \
| sed s,cadenza/,,g > $TMPDIR/graphbody
We’ll need to disentangle that a bit: rg gives us the lines we saw
before: basename.ext:from 'filename'.
The first sed call replaces that by basename -> filename.
The second line resolves relative imports in the same directory:
./filename becomes path/to/filename.
The third line resolves relative imports in the parent directory. There is no resolution for imports from the parent’s parent directory. We don’t need that, and one key for quick *nix tool drafting is to do what you need, not what someone might need sometime (or not).
The fourth line ('s,^(.*) -> (.*)$,\2 -> \1,') swaps the arguments
to improve the graph layout for sfdp graphs: Graphs are drawn in
reverse, and the arrows then pointed backwards so they look as if
they were drawn forwards.
Now we have the edges:
"foo/bar" -> "moo"
"foo/bar" -> "blah"
"moo" -> "foo/bar"
For styling we also need the nodes. We can do that with plain grep:
grep -o '"[^ "]*"$' $TMPDIR/graphbody | sort -u > $TMPDIR/nodes
It’s time to combine them into graphviz format by using a shell-subprocess that automatically concatenates the outputs of the subcommands into one stdout stream:
(echo 'digraph {'; # the parenthesis starts the subprocess
echo ' rankdir=RL';
echo ' graph [overlap=false splines=true]'; # cleaner lines
echo ' node [shape=none fontsize=21]'; # just show the names
cat $TMPDIR/nodes;
echo ' node [fontsize=14]';
echo ' edge [color="#aaaaaacc" dir="back"]'; # reverse the direction, see above
cat $TMPDIR/graphbody;
echo '}' ) > ${TMPDIR}/graph
Now you can graph all the dependencies of your project! Only one call to dot left and we’re done:
dot -Tsvg -o/tmp/dependencies.svg ${TMPDIR}/graph
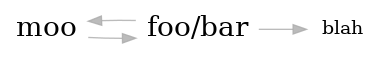
… except that if your project is bigger than foo/bar and baz, this graph tells you nothing (except that you miss spaghetti).
(note also that the non-existent file blah is typeset in a smaller
font, so you can distinguish between your own code — or area of
interest — and external dependencies)
So we need to make that graph actionable: Focus on a region of interest and highlight what we need. This gets into the next section:
subselect and beautify
We need to focus. Let’s say we want to see only the files imported by
or importing moo. The simplest way to do that is to just grep in
the edges:
grep "moo" edges > filtered-edges
To highlight only the target file in the graph, let’s do the same for the nodes:
grep "moo" nodes > filtered-nodes
So it’s filtered: a beautiful graph:

But only for this toy example. In your real code, you might rather
have files like
cadenza/workbook/condition/date-time-condition/date-time-condition.ts
which has 15 imports of similar length. Maybe you only want to see the
filenames — like this:

As before, the tool of choice is sed — generalized so you provide
yourself with all its flexibility:
ARG_GREP='moo'
ARG_SED='s,"[^ ]*/,",g'
cat $TMPDIR/graphbody | grep -E -- "${ARG_GREP}" | sed "${ARG_SED}" ;
And with this we are done! We can create useful graphs of the files and the target files, and they are assembled in less than a second — even if the Javascript-part of your codebase has over 200k LOC in over 2k files. And we can filter and export the graph to svg and open it in inkscape to investigate details.
Done — or almost done? Isn’t something missing?
Would you want to recall a huge command from history and teach your colleagues to use it?
Package it into a tool
The final step turns this into a program. We could rewrite it in C or in Rust or in Java with Graal.
Or we can package it as a script. For this, I turn to conf, an old project of mine that can create a instant autotools setup for bash-scripts (and some other languages).
Just initialize a folder, adjust the script, adapt the argument handling and automate away. First we need a name. I called it depgrapher because that’s what it does:
conf new --vcs git depgrapher # bash is the default language
Now we need an API. I decided to be transparent and raw: The
--grep-argument subselects, the --sed-argument beautifies. That
way people who know grep and sed know what to expect. And for others
it is just how it is. The help output now looks like this:
$ depgrapher --help
depgrapher [-h | --help] [-s | --sed <SED_EXPRESSION>] [-g | --grep <GREP>] WORKDIR
Examples:
search for all files connected to paths that contain 'date-time-condition'
depgrapher --grep 'date-time-condition'
search for all files connected to paths that contain 'import'
depgrapher --grep 'import'
strip some path components:
depgrapher --grep 'import' --sed 's,workbook/,,g;s,workbook-panel/,,g;s,import/,,g'
only show the basenames:
depgrapher --grep 'import' --sed 's,"[^ ]*/,",g'
search for workbook AND conditions
depgrapher --grep 'workbook.*conditions|conditions.*workbook'
I won’t repeat the implementation of commandline parsing because you
can find it at DisyInformationssysteme/depgrapher, and it is as clean
and conventional as I can make it in bash. And because it just does
adjustments of the template that conf provides.
Then plug all those commandline commands into depgrapher.in and add a
final call to inkscape. At the request of a colleague it later
gained the ability to change the viewer. See README.md. Also you can select the graphviz command with --plot CMD, for example to use sfdp for large graphs.
(And yes, the implementation of argument handling is longer than the actual working code. Which isn’t hard, because the working code is just 17 lines. Three of which brimming with ripgrep, grep, sed, and regex.)
Now add your name in configure.ac, commit and push, and you’re done. A nice and small dependency grapher that outperforms most tools out there by doing as little as possible on its own and shelling out to existing tools wherever possible.
And you can install it with autoreconf -i; ./configure; sudo make install.
It’s free to use and adapt on Github under the Apache-2.0 License:
depgrapher - Create partial dependency graphs
A heartfelt thank you to Disy for letting me release the depgrapher as Free Software and for encouraging me to blog about the process!
Have fun depgraphing!
Share via


