
Continuous integration with an evergreen master
Our dev lead said “it would be great if jenkins could reject a commit without having to block the push”. It was an Aarlaubsday and I decided to accept the challenge: „I can do that with Mercurial (hg)“. But let’s start from the use-case.
We use Git with trunk-based development to realize continuous
integration with fast feedback and minimized manual merging: All
developers push into a central Git repository and rebase on pull. Our
continuous integration system (CI) regularly grabs the latest state
and runs tests. This allows it to check all new commits together, so even if the CI takes longer for a test than we need to create and push the next commit, the CI never becomes a bottleneck.
Once the tests are done, we see if the CI reports test failures,
or, worst of all, if the build breaks.
When the build breaks, all who pulled have to either rebase their changes back to an earlier version (error-prone) or wait until someone fixes the repository. Chances are that the one who broke it just left for the weekend (we’ve all been that one; most of us at least). If 30 developers have to spend 5 minutes each to unbreak their repositories, that’s expensive, and the frustration that can cause is even more expensive. How can we fix this?
Many paths lead towards an evergreen master.
- We could use feature branches and only merge when they are complete. But then jenkins would have to check every feature branch and merging changes would be delayed, so we would get more merge conflicts that require manual resolution.
- We could add a hook to block the push until basic tests are run. But then we cannot get the changes of others while the CI runs, so the time between synchronizing our states is prolonged, we get more merge conflicts, and in addition we get a queue of not-yet-accepted pushes.
- We could have the CI remove the breaking changes, forbid adding those commits again, rebase everything that was pushed in the meantime, and require everyone to rebase to the new head. But no one wants this, right? I can almost feel you recoil in terror, so let’s explore the first two options.
Our focus is on the amount of unsynchronized changes: Work of others which we do not have in the local repository yet. We want to minimize these unsynchronized changes because they can cause merge conflicts that require manual resolution, and they cause the final state of the code to diverge from the state the developer saw during work.
Base cost: trunk-based CI after push
The first step before analysing a good path forward is to check the current state. With trunk-based development, the time to see a change from another developer is minimized: After the other developer pushes, you see the change at your next pull (because you need to rebase). A sample interaction with two developers looks like the following:
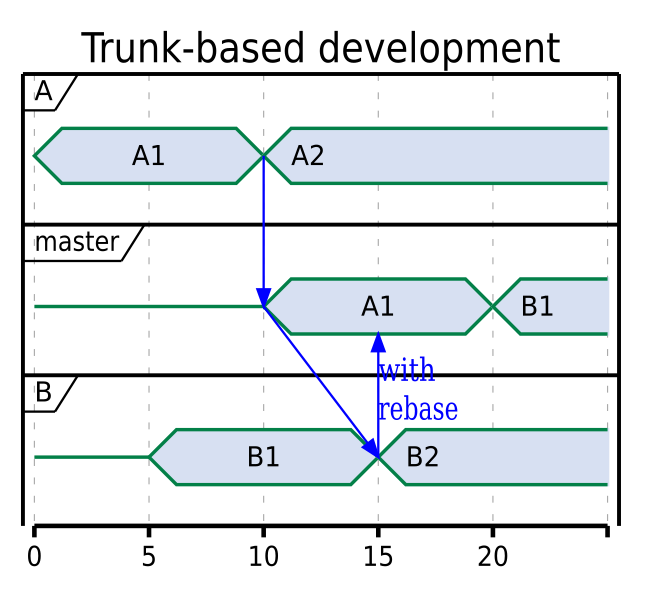
A commits A1 and pushes it to master and starts to work on A2. B commits B1 and tries to push, but master already has A1, so B must rebase B1 on top of A1. When the CI is finished with A1, it starts working on B1.
Investigating the cost of different strategies due to delayed change visibility needs a slightly more realistic scenario:
- At least one bug that turns the build red, impacts another developer, and gets fixed.
- Changes that must be merged together.
- The amount of changes unknown to each of the developers at the end of the discussed time period.
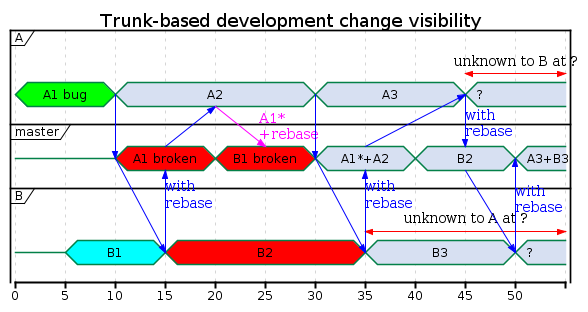
Similar to the basic workflow, A commits A1 and pushes it to master. But here A1 contains a bug which will turn the build red. Then A starts to work on A2. B commits B1 and tries to push, but master already has A1, so B must rebase B1 on top of A1. Then B pushes B1.
When the CI is finished with A1, it reports an error. A quickly shelves away the changes from A2, pulls from master and creates and pushes the fix A1*. Since master already contained B1, A committed the fix on top of B1.
At the end of the period shown here, master contains all pushed changes. The CI checks several changes together: A1* (bug fix to A1) and A2 as well as A3 and B3.
Manual rebase resolution is minimized: B rebases B1 unto A1, so when A has to rebase for the bugfix, the merge between A1 and B1 has already been done by B. That way there is exactly one merging rebase necessary per change, because the result of each rebase is pushed to the shared master branch right after the rebase.
But the CI-run for B1 still contains the bug from A1 which can (and occasionally does) mask later bugs. During development of B2, B has to ignore the bug by A. This is the problem we want to get rid of.
Let’s analyze the options:
Cost analysis, feature branches
The first and most widespread option are feature-branches: Working on separate branches with the CI running tests on the branches. Changes on master are pulled into the feature branches as quickly as possible.
The cost is that feature branches only merge from master, so we only see changes once another feature branch gets merged into master. Let’s check this graphically:
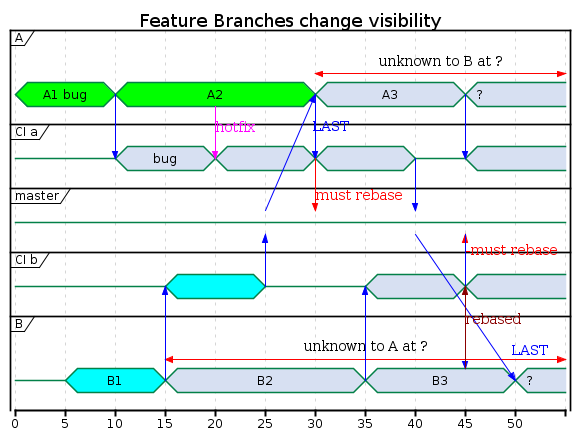
When A does the LAST pull, the changes from B were done against a code base that missed commits A1 and A2. If A touched the same code as B, this pull could require manual rebase resolution, especially with refactoring, the sweep and broom to keep the codebase maintainable.
Similarly, when B does the LAST pull, the changes from A in master were done against a code base which only contained one of the three changes from B.
At the end of the time period, three changes remain unsynchronized: master only contains A1, A2, and B1.
This cost increases, if feature-branches are only merged to master after code-review. In that case the CI-phases can be much longer than the coding-phase.
If you use this model, you must stay vigilant to merge the branches to master quickly, otherwise the changes accumulating in unmerged branches will cause conflicts that become visible in all other unmerged branches at merge-time. If you only merge once a branch is done, you must keep branches short-lived, otherwise you limit your abilities to refactor.
Cost analysis, blocking push
The second option is blocking the push until tests are run successfully — and rejecting pushes on test failures. The cost is that changes are only visible once the tests succeeded for the respective push, and also that pushing could take quite long, so there would be a queue of pushes where a rebase would be required once you’re at the front of the queue. And the CI could no longer run tests for multiple pushes together.
A typical run on our jenkins currently tests changes collected from two to three people, so with blocking pushes, the CI would become a bottleneck. For this evaluation, let’s assume that you can keep your spot at the front of the queue when you have to rebase, and that developers do not have to wait for the result of pushes, but rather keep working and rebase as needed on the side. This requires additional tooling, but similar tooling has already been reported (for example the Chromium Commit queue and Uber’s SubmitQueue). Let’s check the visibility-delay graphically:
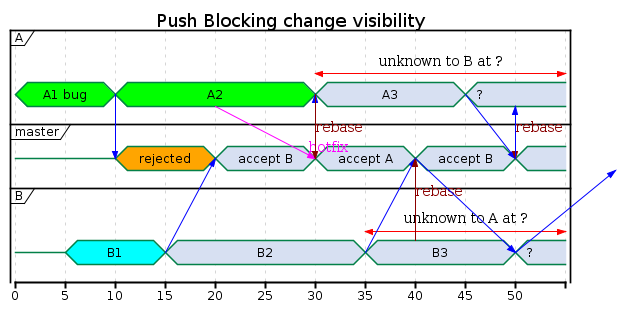
Compared to the feature-branch case, B rebases earlier, so the changes from A were only missing B2. The first rebase by A however has the same conflict potential as with feature branches: the change B1 contained neither A1 nor A2.
The CI cannot combine changes by different people, but in can combine A1* and A2 by the same person.
At the end of the shown period, A and B are both waiting for their pushes to be accepted. In a larger project such waiting causes contention or races at the server.
Satisfactory?
Feature branches and blocking the push both lead to an evergreen master. But feature branches strongly increase the amount of unmerged changes and therefore potential for merge conflicts, while blocking the push moderately increases the amount of unmerged changes, can cause repeated push-races on the server and prevents the CI from checking changes from multiple people in one run.
Just imagine how those diagrams above would look with 30 developers instead of 2.
Feature-branches:
- much more unmerged changes (keep them short-lived!)
Blocking the push:
- more unmerged changes
- push-races
- no change-aggregation by CI
That’s unsatisfactory. We have either lots of additional unmerged commits at any time or 30 people waiting because of the 3 commits a day that might cause build failures.
So maybe we should give that scary third option another look.
The third option: coordinated backout and rebase
In this approach, people can continue to push changes to master while the continuous integration system (CI) runs its tests. If the CI encounters test failures, it directly removes the tested commits. Since master stays open for pushing, there can be commits after the commits which get removed. Those additional commits are rebased. Now all developers also take out the removed commits from their repositories and rebase their work on top of the new commits.
We avoided checking this approach until now, because rebasing published code is a no-go with Git. With Git, this requires force-pushing into a remote branch and preventing the removed commits from entering the repository again by some means.
But what if that coordinated backout-rebase-scheme just worked so the CI could directly take out bad commits? If any tool could do it reliably and transparently?
We would have no blocked pushes and we could synchronize instantly, but a broken build would be repaired by the CI. Even if the committer already left for the weekend, we could get back to a working state with a simple pull once the CI removed the broken commits.
Let’s analyze what this would give us.
Cost analysis: coordinated rebase
The third option is to have the CI automatically remove broken commits, rebase later code on top of the state before the breakage, and continue to take out commits until the tests complete successfully. Then it sends emails to all people who had commits removed in the process and the needed information so they can re-apply the changes locally and push a fixed version.
Also it needs to blacklist all the removed commits so those commits get removed from all developer-repositories, too.
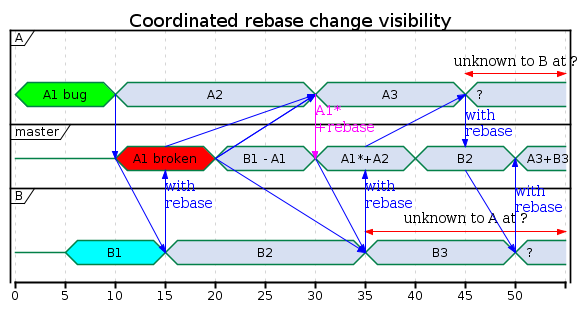
Now when B pushes B1, it’s only necessary to merge a single change from another developer (A1), and when A rebases A1* (the fixed A1) and A2, it’s only necessary to merge combine those with the single change B1.
Conceptually the only one who had to do manual work for fixing this was A. Without broken build the cost is the same as with plain trunk-based-development. With broken build, the only one who has additional manual work is the one who broke the build.
A danger with this approach is that someone might overlook the information by the CI, so a change might get lost.
But the core problem in the implementation process is that now B has to follow the rebase done by the CI, and since this only happens rarely — only when a change by A breaks the build and B pulls before the CI removes it — B will have to read up how to do it. All the wasted effort in manual coordination of such a rebase is horrible.
Can’t we do better? Can’t we automate that?
Yes, we can. It will be the topic of our next article: changeset evolution with Mercurial.
The title image was published by Tim Foster under the Unsplash License.
Share via


