
JUnit 5,
Rust,
GraphML
Aarlaubstag Februar 2016
Bei Disy ist seit Jahren jeder erste Mittwoch im Monat „Aarlaubstag“. Wir nutzen ihn zur selbstständigen Weiterbildung, was bei den Entwicklern typischerweise das Herumexperimentieren mit neuen Tools, Techniken und Ansätzen bedeutet. Hier berichten wir euch vom letzten Aarlaubstag Anfang Februar.
JUnit 5
Vor ein paar Tagen ist die Alpha-Version von JUnit 5 erschienen. Nachdem Disy zum Crowdfunding beigetragen hat und ich bereits vor ein paar Wochen mit dem Prototyp experimentiert habe, wollte ich an diesem Aarlaubstag nachschauen, was sich seitdem getan hat.
Highlights bei den Neuigkeiten
An der Oberfläche nicht viel und das ist gut so! Die durchdachten Änderungen gegenüber JUnit 4 wurden beibehalten. Hier einige Highlights:
- Auf der Suche nach Annotationen berücksichtigt JUnit auch Meta-Annotationen und die mitgelieferten sind ebensolche:
@Target({ ElementType.TYPE, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
@Test
@Tag("fast")
public @interface FastTest { }
@FastTest
void speedTest() {
// ...
}
- Wie man da schon sieht: No more
public! Yay! Test- und Lifecycle-Methoden können jetzt package visible sein. - Um Tests im BDD-Style mit geschachtelten Klassen zu schreiben, braucht es keinen Boilerplate-Code mehr:
class TestingAStack {
// ...
@Nested
class WhenNew {
// ...
@Nested
class AfterPushing {
// ...
}
}
}
- Es ist relativ leicht, eigene Conditions für das bedingte Ausführen von Tests zu schreiben.
- Erweiterbarkeit durch Extensions statt
RunnerundRules verspricht flexiblere und einheitlichere Add-Ons. - Methodenparameter werden injiziert. Das ist großartig und wird sicherlich zu besserem Testcode führen. Mit der Mockito Extension sieht das z.B. so aus:
@ExtendWith(MockitoExtension.class)
class MyMockitoTest {
@BeforeEach
void init(@InjectMock Person person) {
when(person.getName()).thenReturn("Dilbert");
}
@Test
void simpleTestWithInjectedMock(@InjectMock Person person) {
assertEquals("Dilbert", person.getName());
}
}
Integration und Kompatibilität
Die IDE-Integration ist mittlerweile auch soweit.
Mit dem JUnit5-Runner lässt sich ganz einfach eine JUnit4-Testsuite erstellen,
welche die neuen Tests laufen lassen kann:
@RunWith(JUnit5.class)
@Packages({ "net.disy.cadenza" })
public class JUnit5Tests { }
Für die IDEs bleibt damit alles bei JUnit 4 und funktioniert (beinahe) genauso gut wie zuvor. Gradle und Maven Support ist ebenfalls bereits vorhanden.
Version 5 stellt eine öffentliche API für Build-Systeme, etc zur Verfügung, Dadurch sollen Abhängigkeiten auf Interna – die bei JUnit 4 mangels einer solchen API üblich waren – verhindert und die freiere Evolution von JUnit 5 ermöglicht werden.
Zur Kompatibilität ist zu sagen, dass JUnit 5 einen neuen Namespace (aktuell org.junit.gen5.api) besetzt und somit bei den Imports keine Konflikte auftreten können.
Tests der Generationen 4 und 5 können also problemlos im gleichen Projekt verwendet werden.
Ausprobieren
Mehr Informationen zu allem oben genannten und noch mehr gibt es im JUnit 5 User Guide.
Erfahrungen mit der Sprache Rust
Tl;dr: Unrustled
{kind=link}
Ich lese nun schon monatelang immer wieder wie toll die Programmiersprache Rust ist. Man könnte geradezu meinen, dass es einen Hype um diese Sprache gibt. Also habe ich beschlossen, meinen Aarlaubstag dazu zu nutzen mir die Sprache mal etwas näher anzuschauen.
Rust ist nicht ganz neu, sondern schon seit ca. 2010 nutzbar. Mittlerweile in der Version 1.6 verfügbar, ist die Core API auch schon in großen Teilen stabil und sehr gut dokumentiert. Mein Ziel war es innerhalb von einem Tag einen kleinen XML Parser zu schreiben, der eine XML Datei einliest und dann die Baumstruktur der Tags wieder ausgibt.
Hier eine kleine Zusammenfassung meiner Erlebnisse und Beobachtungen:
Pro
- Sehr cooles Build-Tool (cargo). Extrem simpel, robust und mächtig.
- Code-Doku mit Markdown! Erzeugt sehr schöne HTML Seiten aus dem Code.
- Variablen sind per default immutable.
- Keine ungültigen Speicherzugriffe mehr zur Laufzeit (ohne Garbage Collector, nur vom Compiler geprüft).
- Keine Race Conditions mehr bei mehreren Threads.
- Sehr Schnell!
Neutral
- Compiler ist gefühlt sehr hart was die Syntax anbelangt. Bei den meisten anderen Sprachen (z.B. Python oder Perl) musste ich nicht so viel kämpfen bis mein Code ausgeführt wurde.
- Toolsupport wächst langsam, ist aber noch sehr dürftig (keine richtige IDE, Debugger, Linter, …).
Contra
- Kryptische und zeitweise frustrierende Syntax -
fn bar<'a, 'b>(x: &'a mut i32) -> &'b strsoll eine normale, lesbare Funktions-Signatur sein? - Compiler Fehlermeldungen werden sehr schnell unverständlich.
- Doku kann unverständliche Syntaxfehler erzeugen.
- Borrow Checker und Lifetimes haben einen großen kognitiven Zoll. Anstatt mich rein auf die Logik konzentrieren zu können, muss ich mir ständig Gedanken machen was wann mutable ist und von wem referenziert werden darf.
Die ersten Schritte waren trotz Anleitung nicht einfach, sondern eher verwirrend:
- Die Code Beispiele im “Rust Book” sind so elementar, dass sie für mehr als ein “Hello World” nutzlos waren.
- Als ich mir für meine Windows-Umgebung den Compiler herunterladen wollte, musste ich mich zwischen einer MSVC- und GNU-Variante entscheiden, aber ohne einen Hinweis darauf welche für mich besser wäre.
- Das Visual Studio Plugin ist noch experimentell und war für mich kaum zu benutzen (abgesehen vom Syntax-Highlighting).
- Ich habe es auf Biegen und Brechen nicht hinbekommen etwas mit dem standard log-Modul auszugeben.
- Als ich meinen fertigen XML-Parser, der unter Linux problemlos läuft, unter Windows kompiliert hatte, konnte er keine Dateien mehr lesen (Absturz mit “OS Error”). Das war dann auch das Ende eines sehr unterhaltsamen Tages :)
Source
Das grandiose Ergebnis des Aarlaubstages gibt es auch direkt als Download!
Fazit
Die Sprache hat durchaus Potential und einige gute Ansätze, allerdings würde ich sie noch nicht für mehr als ein paar Spielereien nutzen. Die Sprache hat eine sehr hohe Lernkurve und geht vermutlich auch geübten Entwicklern nicht so gut von der Hand wie die Alternativen.
GraphML programmatisch erzeugen
Aktuell bringt Disy seine Expertise in Geoinformations- und Datenbanksystemen in einem Projekt für eine Bundesbehörde ein und verarbeitet in dem Rahmen einige Terabyte GIS-Daten. Diese müssen bereinigt, verknüpft und abschließend fachlich verarbeitet werden. Die Datenmanipulation geschieht weitestgehend mit PL/SQL in einer Oracle-Datenbank, während die Ablaufsteuerung in Java implementiert ist.
Visualisierung
Der Ablauf ist in einige thematische Bereiche aufgeteilt, wovon jeder als Pipeline, bestehend aus einer stattlichen Anzahl Einzelschritte, modelliert ist. Diese Schritte und deren Abhängigkeiten sind im Code durch Enums ausgedrückt. Dadurch können sie analysiert werden ohne das System tatsächlich laufen zu lassen, was gleich noch wichtig wird.
Zur Veranschaulichung haben wir zu jedem Bereich ein yEd-Diagramm angelegt, das die Abhängigkeiten zwischen den einzelnen Schritten zeigt. Es manuell zu erstellen und zu pflegen, ist jedoch monoton und zeitaufwändig.
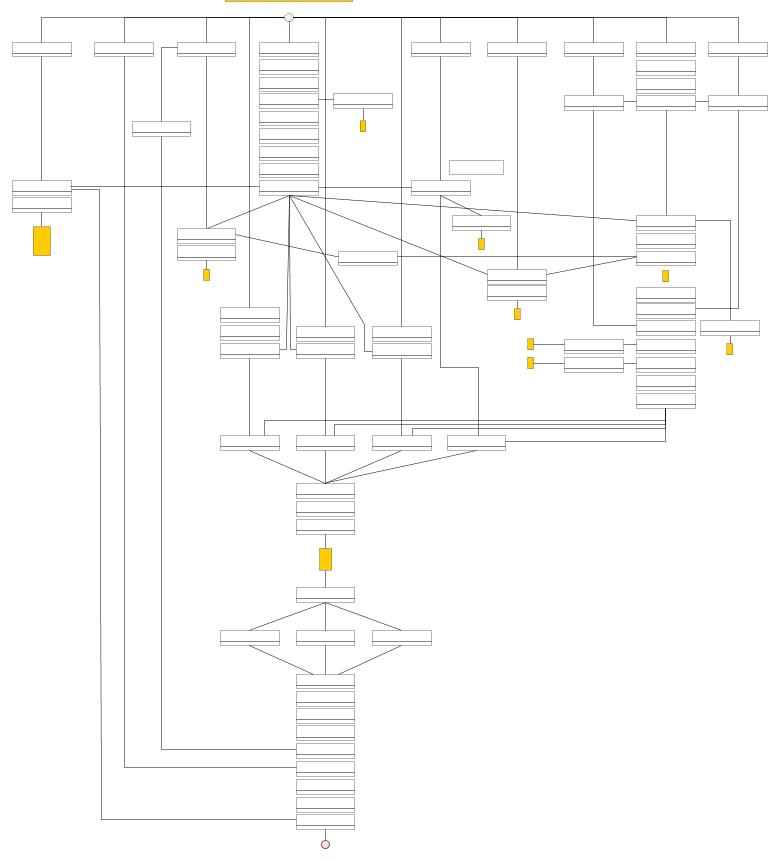
Automate All The Things!
Am Aarlaubstag wollte ich schauen, ob sich da nicht was machen lässt. Die Enums auszulesen und so den Abhängigkeitsgraph im Speicher zu erzeugen ohne das System laufen zu lassen ist trivial.
Statt das GraphML-Schema zu verwenden, wollte ich austesten wie weit man mit zeilenweiser Verarbeitung mit NIO2 und Streams kommt. Also habe ich aus einer bestehenden .graphml-Datei einige Templates für die Knoten herausgezogen. Damit war es dann ein Leichtes, den Graph zu erstellen.
UnaryOperator<Stream<String>> replacePlaceholders() {
return templateLines -> templateLines
.map(l -> l.replace(STEP_NAME, beautify(stepName)))
.map(l -> l.replace(STEP_TABLE, beautify(stepTable)))
.map(l -> l.replace(NODE_TAG, nodeTagWithId(nodeId)))
.map(l -> l.replace(Y_COORDINATE, yCoordinate));
}
Der Einfachheit halber habe ich die Knoten in einer vertikalen Reihe angeordnet und auf yEd’s hierarchischen Layouter gesetzt. Zu Recht, denn der erzeugt Ergebnisse, die vom manuellen Graph oben qualitativ kaum zu unterscheiden sind.
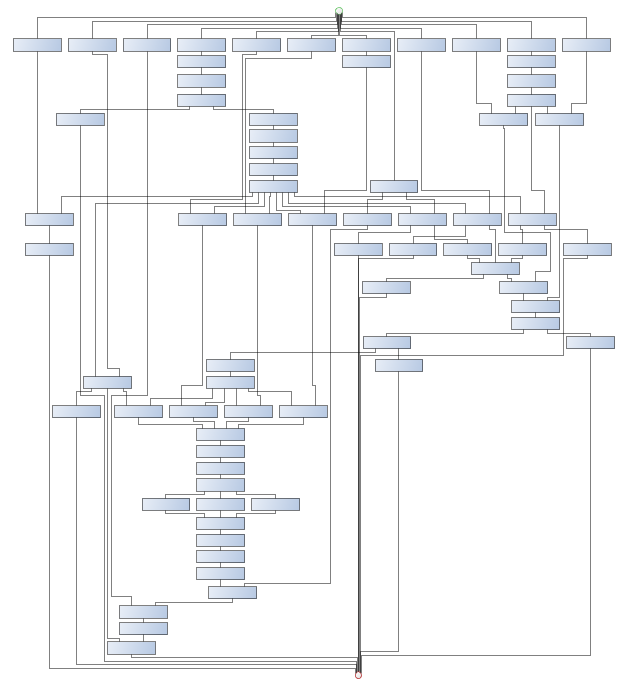
Ausblick
Mit diesem Tool bin ich recht zufrieden, aber leider können damit nur neue Graphen erzeugt werden. Vielleicht nehme ich mir in Zukunft die Zeit, bestehende graphml-Dateien einzulesen, damit manuelle Verschönerungen nicht verloren gehen.
Das Titelbild heißt Double Spiral with Random Outgrowth 1 und wurde von Ehsanul Hoque unter CC-BY 2.0 veröffentlicht. Wir haben es horizontal skaliert.
Teilen via


